As a VMware Architect, I must understand how my recommended infrastructure performs. As a VMware Systems Engineer, I need to know how the platform performs and which changes I can make to ensure the VMs perform better. One of the performance-focused tools is ESXi NUMA. This article will look at NUMA Scheduling, what it is, and how we can utilize this feature.
You should read more on my blog, where I focus on the VM perspective, and perhaps this article focuses on another VMware Performance topic, CPU Ready.
What is NUMA
From VMware website we can read:
NUMA systems are advanced server platforms with more than one system bus. They can harness large numbers of processors in a single system image with superior price to performance ratios.
For the past decade, processor clock speed has increased dramatically. A multi-gigahertz CPU, however, needs to be supplied with a large amount of memory bandwidth to use its processing power effectively. Even a single CPU running a memory-intensive workload, such as a scientific computing application, can be constrained by memory bandwidth.
This problem is amplified on symmetric multiprocessing (SMP) systems, where many processors must compete for bandwidth on the same system bus. Some high-end systems often try to solve this problem by building a high-speed data bus. However, such a solution is expensive and limited in scalability.
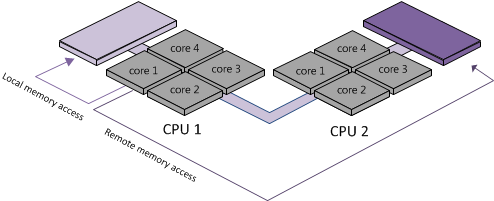
NUMA is an alternative approach that links several small, cost-effective nodes using a high-performance connection. Each node contains processors and memory, much like a small SMP system. However, an advanced memory controller allows a node to use memory on all other nodes, creating a single system image. When a processor accesses memory that does not lie within its own node (remote memory), the data must be transferred over the NUMA connection, which is slower than accessing local memory. Memory access times are not uniform and depend on the location of the memory and the node from which it is accessed, as the technology’s name implies.
How ESXi NUMA Scheduling works
ESXi NUMA scheduler dynamically balances processor load and memory locality or processor load balance. The goal of the NUMA scheduler is to maximize local memory access and attempts to distribute the workload as efficiently as possible.
- Each VM managed by the NUMA scheduler is assigned a home node. A home node is one of the system’s NUMA nodes containing processors and local memory.
- When memory is allocated to a virtual machine, the ESXi host preferentially allocates it from the home node. The virtual CPUs of the virtual machine are constrained to run on the home node to maximize memory locality.
- The NUMA scheduler will dynamically change a virtual machine’s home node to respond to changes in system load.
- Migrations of VMs due to CPU can cause more of its memory to be remote, and the scheduler will dynamically migrate the virtual machine’s memory to its new home node to improve memory locality.
- The NUMA scheduler may swap virtual machines between nodes when this improves overall memory locality.
The NUMA scheduling and memory placement policies in ESXi can manage all virtual machines transparently, so administrators do not need to explicitly address the complexity of balancing virtual machines between nodes.
For a VM with more virtual processors than the number of physical processor cores available on a single hardware node NUMA scheduler spans such a virtual machine to be managed by multiple NUMA clients at once, each client is managed by the scheduler as a normal NUMA node.
Dynamic Load Balancing and Page Migration
ESXi combines the traditional initial placement approach with a dynamic rebalancing algorithm. Periodically (every two seconds by default), the system examines loads of the various nodes and determines if it should rebalance the load by moving a virtual machine from one node to another.
The rebalance selects an appropriate virtual machine and changes its home node to the least loaded node. The rebalance moves a virtual machine with some memory on the destination node when it can. From that point on (unless it is moved again), the virtual machine allocates memory on its new home node and runs only on processors within the new home node.
When a virtual machine moves to a new node, the ESXi host immediately migrates its memory. It manages the rate to avoid overtaxing the system, particularly when the virtual machine has little remote memory or when the destination node has little free memory available.
NUMA on ESXi
Let us look at what all this means in reality. How do I know the NUMA setup for my ESXi hosts?
This host has a dual-socket Intel(R) Xeon(R) Gold 5220 CPU @ 2.20GHz, a CPU with 18 physical cores per socket, and the host has 765 GB of RAM. Running ESXtop, I get a good overview of the NUMA nodes of this host.

I see two NUMA nodes, each with 391838 MB of RAM accessible. From the CPU architecture we know that there are 18 Cores in each socket. Which gives us about 21 GB of RAM per Core.
If we within the Esxtop command, press m, press f, and then select G, we get an overview of all the VMs running on the ESXi host and which NUMA node they are assigned to.
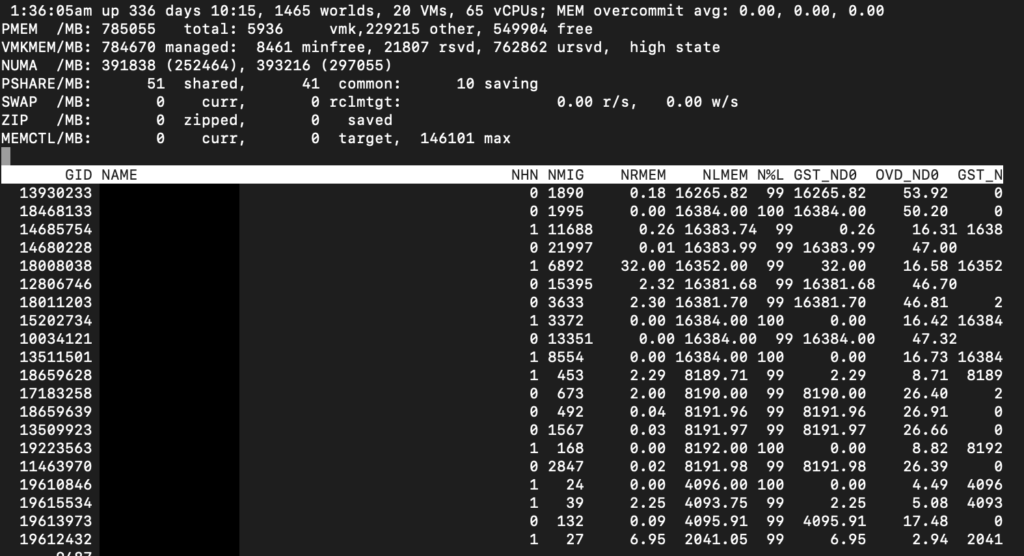
The above screen shows me the NUMA nodes in use by the VMs of the host (blacked out).
| Metric | Explanation |
|---|---|
| NHN | Current Home Node for virtual machine |
| NMIG | Number of NUMA migrations between two snapshots. It includes balance migration, inter-mode VM swaps performed for locality balancing and load balancing |
| NRMEM (MB) | Current amount of remote memory being accessed by VM |
| NLMEM (MB) | Current amount of local memory being accessed by VM |
| N%L | Current percentage memory being accessed by VM that is local |
| GST_NDx (MB) | The guest memory being allocated for VM on NUMA node x. “x” is the node number |
| OVD_NDx (MB) | The VMM overhead memory being allocated for VM on NUMA node x |
From the list above, we can understand if we have optimally or non-optimally configured VMs. In this setup, they primarily run on the local NUMA node, with very little remote memory access. The ESXi hosts run primarily VMs with smaller CPU and RAM configurations, so what we see on the ESXtop interface correlates well with the VM configurations.
We can verify the NUMA Corea allocation with commands like CoreInfo and numactl.
Virtual NUMA
vSphere includes support for exposing virtual NUMA topology to guest operating systems, which can improve performance by facilitating guest operating system and application NUMA optimizations.
Virtual NUMA topology is available to hardware version 8 VMs and is activated by default when the number of virtual CPUs is greater than eight.
The first time a virtual NUMA activated virtual machine is powered on. Once a VMs virtual NUMA topology is initialized, it does not change unless the number of vCPUs in that virtual machine is changed.
The virtual NUMA topology does not consider the memory configured to a virtual machine. The virtual NUMA topology is not influenced by the number of virtual sockets and number of cores per socket for a virtual machine.
Virtual NUMA Controls
For virtual machines with disproportionately large memory consumption, you can use advanced options to override the default virtual CPU settings.
You can add these advanced options to the virtual machine configuration file.
| Option | Description | Default Value |
|---|---|---|
| cpuid.coresPerSocket | Determines the number of virtual cores per virtual CPU socket. This option does not affect the virtual NUMA topology unless numa.vcpu.followcorespersocket is configured. | 1 |
| numa.vcpu.maxPerVirtualNode | Determines the number of virtual NUMA nodes by splitting the total vCPU count evenly with this value as its divisor. | 8 |
| numa.autosize.once | When you create a virtual machine template with these settings, the settings remain the same every time you then power on the virtual machine with the default value TRUE. If the value is set to FALSE, the virtual NUMA topology is updated every time it is powered on. The virtual NUMA topology is reevaluated when the configured number of virtual CPUs on the virtual machine is modified at any time. | TRUE |
| numa.vcpu.min | The minimum number of virtual CPUs in a virtual machine that are required to generate a virtual NUMA topology. A virtual machine is always UMA when its size is smaller than numa.vcpu.min | 9 |
| numa.vcpu.followcorespersocket | If set to 1, reverts to the old behavior of virtual NUMA node sizing being tied to cpuid.coresPerSocket. | 0 |
Specifying NUMA Controls
ESXi provides three sets of controls for NUMA placement, so that administrators can control memory and processor placement of a virtual machine.
You can specify the following options.
- NUMA Node Affinity when you set this option, NUMA can schedule a virtual machine only on the nodes specified in the affinity.
- CPU Affinity when you set this option, a virtual machine uses only the processors specified in the affinity.
- Memory Affinity when you set this option, the server allocates memory only on the specified nodes.
A VM is still managed by NUMA when you select NUMA node affinity. Its CPU and Memory can only be scheduled on the nodes specified configuration. When selecting CPU or Memory Affinity, the VM is no longer managed by NUMA. Removing the CPU or Memory affinity setting brings the VM back into being managed by NUMA.
Editing of NUMA Affinity will interfere with the Resource management that automatically happens within a vSphere Cluster. A lack of understanding can make some VMs perform poorly due to poorly managed affinity settings.
What now – how do we use this knowledge
Understand the NUMA configurations on your hosts. Plan the workloads to match within one NUMA node. If that isn’t possible, there are compensating controls that bring their complexity. When we as architects design an infrastructure for our customers, it is essential to understand the workloads to be able to design for the best possible performance
With the concept of local and remote memory in mind, we know that VMs perform best when memory is accessed locally. The VM vCPU and memory configuration should reflect the workload requirements to extract the performance from the system. Typically VMs should be sized to fit in a single NUMA node.
Suppose workloads require more memory or CPU than one NUMA node can provide. In that case, we can either edit the NUMA settings per VM, let the VM be spanned between more NUMA nodes, or choose a different CPU Architecture to support the workloads if it is a brownfield approach pushing Application Owners to use VM Configurations to run their VM within the local NUMA node.
We know from above that the hosts specified here have 18 Cores within a NUMA node. If we choose a VM CPU configuration with more than 18 CPU Cores or Sockets, the combination of sockets and cores within a VM plays no role. Now the NUMA Scheduler is not able to place the VM solely on the local NUMA node. The VM will not benefit from the local memory optimization and it’s possible that the memory will not reside locally, creating added latency by crossing the intersocket connection to access the memory. This problem was probably more previliant on earlier systems that had CPU Sockets with less cores, on modern systems this challenge gets less likely to occur, but it is still important for us to be aware of it.
What will happen if we assign a VM more memory than what is available in the local NUMA node? The memory will be scattered on remote NUMA nodes, which can reduce the system’s performance. Not aligning the VM memory configuration with the local NUMA memory size will stop the ESX kernel from using NUMA optimizations.
As mentioned, with modern CPU technology, the NUMA node sizes are usually larger, and the chance for the business to create larger VMs than the NUMA node is reduced. However, it still happens. The VMs may start well-sized, and then someone wants more CPU or RAM to increase performance. Due to the NUMA size, it isn’t given that more CPU and RAM make the VM perform better.