So we designed, or at least we thought about designing, a VMware Stretched Cluster in the last post. Now we will look into which failure scenarios we have designed a solution to protect us against.
Assumptions:
For this blog post we assume that we have designed an environment with high focus on disaster avoidance and that we also had the ability to deploy it in the most favorable way.
- Three seperate failure domains
- Redundant power to the DC
- Redundant ISP/WAN connections to the DC
- Redundant Fiber between DCs
- Redundant Network in DCs
- Redundant Cooling in DCs
There may be more aspects that goes into the assumptions. However the goal is that there are no single point of failures at any stage interacting with the infrastructure.
In the last post we discussed cost and this is beyond the infrastructure itself a significant cost driver.
High-level design drawing:
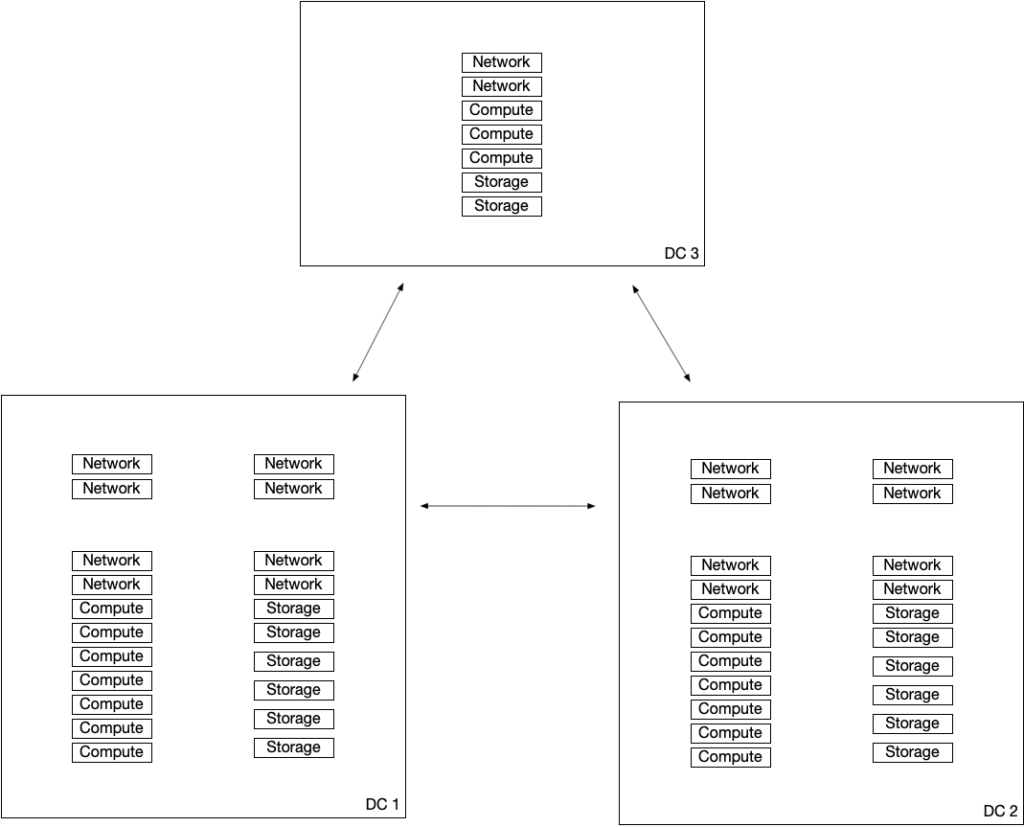
DC 1 & DC 2 holds infrastructure Compute, Storage, and Networking that each are designed to be able to hold all VMs running on the infrastructure, and still have extra hardware for redundancy. DC 3 holds a resilient infrastructure to host the Witness for the Cluster spanned between DC 1 & DC 2.
Failure Scenario 1 – Failure of a whole DC
If something happens, like fire, flooding, hardware errors etc that would take out one DC, let us say DC 2. The VMs running on DC 1 will be unaffected by the outage in DC 2. The VMs running in DC 2 will reboot on DC 1, by the help of VMware HA.
The Witness will tell the surviving leg of the stretch cluster, DC 1, that it now is primary and that it should take over as active.
If the storage has Synchronous replication and the architecture is Uniform, any write operation is accessible from any of the Compute nodes and all the VMs will reside both in DC 1 and DC 2.
Failure Scenario 2 – Failure of ESXi, Network, or Storage on one DC
Like any properly configured VMware infrastructure there are spare nodes within each DC in this solution as well. If there is hardware failure in say DC 1, VMware HA will migrate VMs off failed hardware onto surviving hardware.
If the surviving hardware on say DC 1 is not enough to support the workloads that need to run there it will lead us into Failure Scenario 1.
There are many variations of this that can happen. The point of disaster avoidance is that the every aspect of the datacenter and Infrastructure components are designed to at least have two paths for everything in each Data Center. So in case you loose all or to much in one Data Center you have the second location that has all the hardware needed to run all the workloads and still handle loss of hardware components within that DC.
Patching
User initiated failovers can be really useful in case of maintenance or patching activities. Failover all workloads from say DC 2 to DC 1. The path forward would something like this, different technology has different ways of doing it, failover the storage component to only use storage in DC 1. Disable DRS on ESXi nodes, this is done to ensure that VMs do not move over to other nodes on DC 2 as they go into maintenance mode. Put the ESXi hosts of DC 2 in Maintenance mode. Enable DRS to ensure good health on nodes in DC 1.
When the activity is done. Fail the storage back, and give time for the storage to get synchronized Once the storage is operational on both sides of the cluster, put the ESXi nodes on DC 2 out of maintenance mode. DRS will synchronize the VMs back to DC 2 based upon existing Affinity rules.
Disaster Avoidance & Disaster Recovery
For areas that can be affected by Tornadoes or other catastrophic disasters having a Stretched Cluster may not be enough. We know from one of the requirements that a Stretched Cluster requires no more than 5 ms latency between the two Infrastructures within the solution. So the two Data Centers in a Stretched Cluster needs to have some proximity.
Adding a Disaster Recovery aspect to the solution, like VMware SRM will bring another layer of resilience to the solution. SRM will keep a copy of the VM up to date. If both of the Stretched Cluster DCs would fail SRM would restore the VMs to the DC it replicates to. This DC can be further away, please take a look at the SRM VMware datasheet. I will likely take a deep dive into SRM in a future blog post.
Conclusion
This is very high level. We could have looked at network isolation,disk shelf failure, power failure, cooling failure, etc. It all goes back to the design and architecture of the disaster avoidant infrastructure. If you double down on setting up everything redundant you will have an infrastructure that will survive close to any scenario that will be able to provide you a platform where VMs don’t go down. The application may stop due to errors within the OS or within the application itself. This should be addressed with application load balancing or clustering.
The