Previously, we looked at VMware vSphere performance metrics. NUMA Scheduling and CPU Ready For the article about CPU Ready I got a comment and a reference to a VMware White Paper on CPU Scheduler. Page 10 in that document addresses CPU Co-Scheduling, which triggered this article.
What is Co-Scheduling
Co-scheduling is a mechanism that enables the efficient execution of multiple virtual machines (VMs) on a shared physical host. It involves coordinating the scheduling of vCPUs (virtual CPUs) of different VMs to optimize resource utilization and ensure fair access to CPU resources.
Co-scheduling works by dividing the physical CPU resources into time slices or scheduling intervals. Each time slice is typically a few milliseconds long and is further divided into smaller time slots, usually in the order of microseconds. During each scheduling interval, the hypervisor schedules the execution of vCPUs across all running VMs.
Co-scheduling aims to minimize the interference between vCPUs of different VMs, preventing resource contention and maximizing the overall performance of the virtualized environment. To achieve this, vSphere uses several techniques:
- Co-stop: Co-stop is a metric that measures the time vCPUs spend waiting for their scheduled time slots during a scheduling interval. By tracking co-stop values for each VM, vSphere can identify cases where co-scheduling is inefficient, such as when multiple vCPUs from the same VM are waiting for their turns to execute. This information allows vSphere to make scheduling adjustments to improve performance.
- CPU Affinity: vSphere supports CPU affinity settings, which allow administrators to assign specific vCPUs to specific VMs. This feature ensures that vCPUs of critical or latency-sensitive VMs are scheduled on dedicated physical CPU cores, minimizing interference from other VMs. CPU affinity can be configured at the vSphere level or the VM level, depending on the desired level of control.
- NUMA Awareness: Non-Uniform Memory Access (NUMA) is a memory architecture commonly found in modern multi-socket servers. vSphere’s co-scheduling considers the NUMA topology of the underlying hardware to optimize memory access for VMs. Co-scheduling reduces memory latency and improves overall performance by aligning vCPUs and memory allocations based on the NUMA layout.
Co-Stop
Here are two common methods to measure co-stop and steps to reduce co-stop time for a VM:
- vSphere Performance Charts:
- Access the vSphere Web Client or vSphere Client and navigate to the host or cluster running the VM.
- Go to the “Monitor” tab and select “Performance” > “Advanced” > “Performance Charts.”
- Under the “Chart” tab, locate and select the “CPU” metric category.
- Look for the “Co-stop” metric within the available CPU performance counters.
- Adjust the time range as needed and observe the co-stop values over time.
- vSphere CLI and PowerCLI:
- Use the vSphere CLI or PowerCLI to gather performance data and retrieve co-stop information programmatically.
- The
esxtopcommand-line utility can be used to collect real-time performance data, including co-stop values, by running the command:esxtop -a -c <num_samples> -d <sample_duration>. - PowerCLI provides a rich set of cmdlets to automate performance data retrieval. For example, the
Get-Statcmdlet can be used to retrieve co-stop values for a VM.
To reduce the co-stop time for a VM and improve performance, you can consider the following steps:
- Ensure Sufficient CPU Resources:
- Allocate an appropriate number of vCPUs to the VM based on its workload requirements.
- Avoid overcommitting CPU resources, which can lead to increased co-stop times due to resource contention.
- Adjust CPU Affinity:
- Use CPU affinity settings to allocate specific physical CPU cores to the VM, minimizing interference from other VMs.
- Configure CPU affinity at the vSphere or VM levels to achieve the desired level of control.
- Optimize CPU Scheduling:
- Review and fine-tune CPU scheduling settings and policies in vSphere to improve co-scheduling efficiency.
- Adjust parameters like CPU shares, limits, and reservations to ensure fair resource allocation.
- NUMA Alignment:
- Understand the NUMA topology of the underlying physical host and align VM’s vCPUs and memory allocations accordingly.
- This helps reduce memory latency and improves overall performance, indirectly impacting co-stop times.
- Monitor and Analyze Performance:
- Continuously monitor the co-stop metric for the VM to identify patterns and trends.
- Leverage performance analysis tools like vRealize Operations Manager to gain deeper insights into resource utilization and identify optimization opportunities.
By implementing these steps, you can help reduce the co-stop time for a VM, improve CPU scheduling efficiency, and enhance overall performance in your vSphere environment.
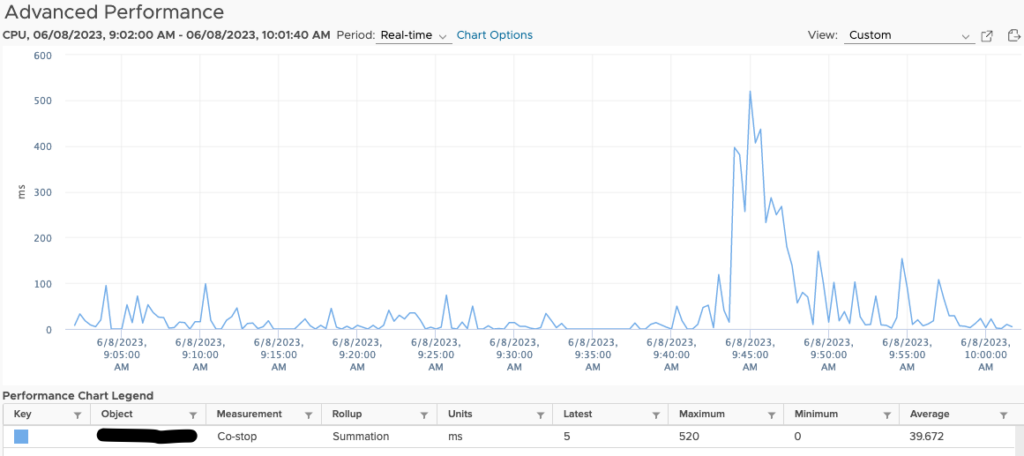
How do co-stop and CPU Ready relate
CPU Ready and Co-stop are performance metrics related to CPU scheduling and can provide insights into virtual machines (VMs) performance and resource contention.
CPU Ready: CPU Ready is a metric measuring the time a VM is ready to run but is waiting for a physical CPU to become available. High CPU Ready values indicate the VM is experiencing resource contention, leading to performance degradation and increased latency.
Co-stop: Co-stop is a metric that measures the amount of time vCPUs (virtual CPUs) spend waiting for their scheduled time slots during a scheduling interval. It indicates the time spent waiting for execution within the VM due to contention with other vCPUs from the same VM.
When CPU Ready values are high, it generally indicates that the host’s CPU resources are oversubscribed and VMs are waiting in a queue to access the physical CPUs.
In other words, high CPU Ready values at the host level can contribute to increased Co-stop times at the VM level.
Monitoring and analyzing both CPU Ready and Co-stop metrics can help identify CPU scheduling inefficiencies and resource contention issues and assist in making optimization decisions such as adjusting CPU allocations, optimizing VM placement, or fine-tuning CPU scheduling settings to improve overall performance in a virtualized environment.
CPU Affinity
In virtualization and multi-core processors, CPU affinity refers to the ability to assign specific CPU cores or threads to a particular process or virtual machine (VM). It allows administrators to control the allocation of CPU resources and optimize performance by ensuring that specific processes or VMs run on dedicated or preferred CPU cores.
CPU affinity can be set on a VM using this methodology:
Browse to the virtual machine in the vSphere Client.
To find a virtual machine, select a data center, folder, cluster, resource pool, or host.
Select VMs.
Right-click the virtual machine and click Edit Settings.
Under Virtual Hardware, expand CPU.
Under Scheduling Affinity, select physical processor affinity for the virtual machine.
Use '-' for ranges and ',' to separate values.
For example, "0, 2, 4-7" would indicate processors 0, 2, 4, 5, 6 and 7.
Select the processors where you want the virtual machine to run and click OK.CPU affinity provides several benefits:
- Reduced Interference: By assigning specific CPU cores or threads to critical processes or VMs, CPU affinity minimized interference from other processes or VMs running on the same physical host, leading to improved performance and reduced latency.
- Cache Utilization: CPU affinity can enhance cache utilization by ensuring that the data and instructions accessed by a process or VM remain in the cache of the assigned CPU cores. This reduces cache thrashing and improves overall performance.
- Deterministic Behavior: With CPU affinity, processes or VMs are guaranteed to run on specific CPU resources consistently, which can benefit latency-sensitive workloads requiring predictable execution.
However, using CPU affinity judiciously and considering the overall resource utilization and workload characteristics is important. It is important to ensure even utilization of CPU resources.
NUMA Awareness
NUMA (Non-Uniform Memory Access) Awareness is a key feature that optimizes performance in virtualized environments by taking advantage of the underlying NUMA architecture of the physical hardware.
Here are the key aspects of NUMA Awareness in vSphere 7:
- Enhanced NUMA Scheduling: vSphere 7 employs advanced NUMA-aware scheduling algorithms that consider the NUMA topology of the physical host and the resource requirements of virtual machines (VMs). The scheduler aims to allocate vCPUs and memory to the appropriate NUMA nodes to minimize memory access latency and optimize performance.
- vNUMA Topology Presentation: vSphere 7 presents a virtual NUMA (vNUMA) topology to each VM, based on the underlying physical NUMA architecture. The vNUMA topology matches the number of NUMA nodes, CPU cores, and host memory configuration. This ensures that the VM’s vCPUs and memory align with the NUMA nodes, allowing efficient resource utilization.
- Automatic vNUMA Configuration: When a VM is powered on, vSphere 7 automatically configures the vNUMA topology based on the VM’s assigned resources. If the VM’s resource configuration exceeds the capacity of a single NUMA node, vSphere 7 intelligently distributes the resources across multiple NUMA nodes to maintain performance and avoid resource imbalance.
- NUMA Load Balancing: vSphere 7 includes advanced load balancing mechanisms to monitor and manage CPU and memory utilization across NUMA nodes. If an imbalance is detected, vSphere 7 can automatically migrate VMs, adjust resource allocations, or make scheduling decisions to rebalance the workload and optimize performance.
- NUMA vMotion: vSphere 7 introduces NUMA-aware vMotion, allowing VMs to be live-migrated between hosts while preserving the NUMA topology. This feature ensures that the vCPUs and memory of a VM maintain alignment with the NUMA architecture during the migration process, optimizing performance after the migration is complete.
Summary
Rightsizing is and has always been a crucial part of Virtualization. Systems with VMs that have high vCPU counts may have worse performance than systems with VMs with low vCPU counts. Physical CPUs play a big role here. However, if the VMs are correctly configured based on the platform they are running on, and they are as nimble as possible regarding resource allocation, they will perform better than large non-optimized VMs.