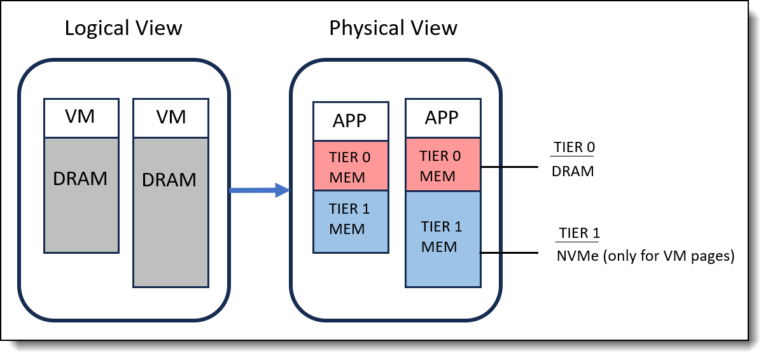
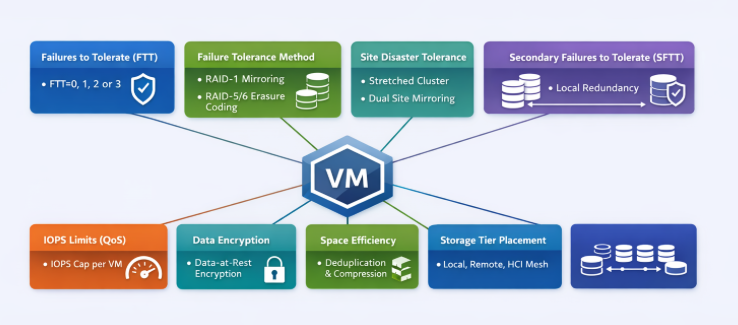
What is Disaster Avoidance
Disaster avoidance is about the efforts to prevent a disaster from happening in the first place. The focus lands on resilience instead of recovery. For applications and Infrastructure, it is the ability to keep the services running even if disasters hit. The more disaster you plan to be able to avoid having an impact on the power of your infrastructure to deliver running VMs and Applications, the more resiliency you need to build into the platform.
For all VMware Engineers and Architects, the concept n-1 is self-explaining. The whole concept of having a 3-node vSphere Cluster is to have an infrastructure that can survive the loss of 1 node. If you have a three-node cluster, you plan that your workloads cannot consume more than 2 of the nodes, and you can lose one node and still be operational. This concept gets applied to Storage, to network, to power, to ISP/WAN, etc – of Course the more resilience you plan the more complex infrastructure.
Service Level Agreement (SLA) is a driver for the design here. The less downtime an application can handle, the more resilience you need to build into the platform. Understanding the appetite for outages from the business is vital, but also communicating that higher resilient solutions bring the cost up.
What is Disaster Recovery
Unlike Disaster Avoidance, Disaster Recovery or DR focuses on how to recover after we the infrastructure has failed beyond the ability to operate, and the applications have to be brought up on a different platform to be able to provide services again. The keywords are Recovery Time Objective (RTO) and Recovery Point Objective (RPO). RTO is a measure for how quickly after and outage an application must be available again. RPO refers to how much data loss your application can tolerate. Both are usually measured in hours. If we loose a Data Center, for say a fire, and we have Application X running there, the RTO may be say 5 hours. Which then means that the application needs to be restored and operational within 5 hours in the DR site for the RTO to be met. The RPO for the same application may be higher or lower based upon the transactions it has. For this Example we say the RPO is 12 hours. This means that we as a business need to have a mechanism, like backup, to ensure that the data for the Application in the DR site is never older than 12 hours. RTO and RPO becomes desisive metrics for how we design our backup and our DR capabilities.
VMware Infrastructure Considerations
When it comes to Disaster Avoidance, we must design it into the infrastructure platform, the Data Center design, Into the building, etc. Which of course makes greenfield much easier than brownfield.
What is the Uptime requirement for your system
| Availability Level | Allowed downtime per year |
| 90% | 36.5 days |
| 95% | 18.25 days |
| 99% | 3.65 days |
| 99.5% | 1.83 days |
| 99.9% | 8.76 hours |
| 99.95% | 4.38 hours |
| 99.99% | 52.6 minutes |
| 99.999% | 5.26 minutes |
The less allowed downtime is per year, the more resilient system needs to be built. Requirements need to be worked on to ensure that the infrastructure and VMware setup is produced under the right conditions. It can be costly to underestimate the downtime you can handle and expensive to overestimate.