In previous articles, I have looked at the difference between Disaster Avoidance and Disaster Recovery and Design considerations for Disaster avoidant infrastructure.
This article will look at a solution that can be the best choice if a high level of Disaster Avoidance is needed. As we learned from previous articles, disaster avoidance or massive system resiliency drives complexity and cost.
The VMware Stretched Cluster, aka the VMware Stretched Metro Cluster (vMSC)
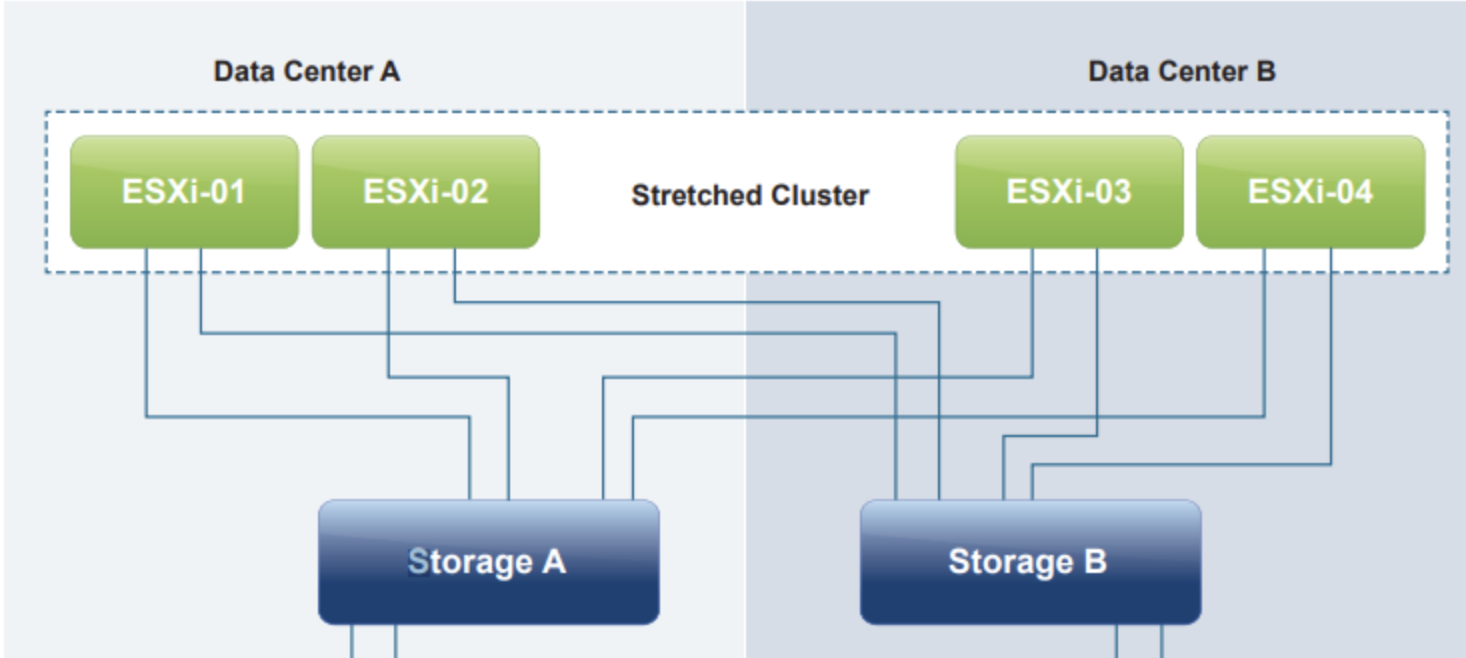
A stretched cluster is a deployment model in which two or more host servers are part of the same logical cluster but in separate geographical locations, usually two sites. The shared storage must be reachable on both sites to be in the same cluster.
In the case of a planned migration, such as in the need for disaster avoidance or data center consolidation, using stretched storage enables zero-downtime application mobility.
In the case of a site disaster, vSphere HA will provide VMs recovery on the other site.
Before going into requirements and configurations. Let us grasp it from a Conceptual design.
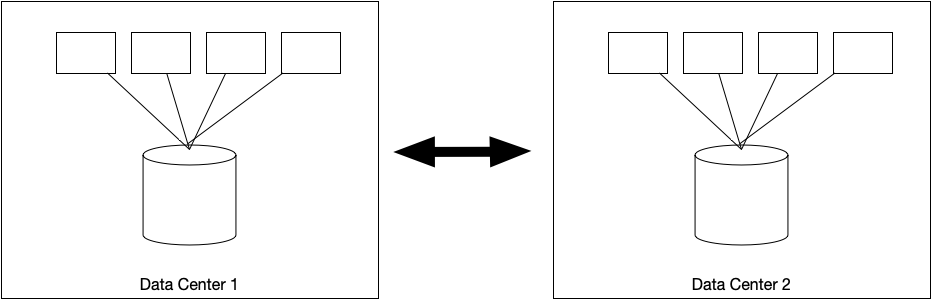
We have one side, Data center 1, with 4 compute nodes and one storage solution. We also have the same in Data Center 2, and in between, we have a mechanism for synchronization. Already here we see we will need to have the same capabilities in DC1 and DC2 to be able to have a successful stretched cluster.
Requirements
There are some basic design requirements for a Stretched Cluster solution:
- Storage connectivity using Fibre Channel, iSCSI, NFS, and FCoE is supported.
- The maximum supported network latency between sites for the vSphere ESXi™ management networks is 10 ms round-trip time (RTT).
- You need vSphere Enterprise Plus licensing enabling vSphere vMotion, and vSphere Storage vMotion, to support a maximum of 150 ms round-trip time. With vSphere standard licensing, the supported latency is only 4ms.
- The most commonly supported maximum RTT for storage systems is 5ms.
- The vSphere vMotion network has a 250 Mbps of dedicated bandwidth per concurrent vMotion session requirement.
- Only legacy FT is supported, SMP FT is not supported on vMSC.
- Note that when a DRS VM/Host rule is created for a VM both the primary as well as the secondary FT VM will respect the rule!
- Storage IO Control is not supported on a vMSC enabled datastore
- Note that SDRS IO Metric enables Storage IO Control, as such this feature needs to be deactivated
Within the storage solution, a given data store must be accessible, read, and written simultaneously from both sites. The vSphere hosts must be able to access data stores from either site transparently and without impacting ongoing storage operations.
This design demand precludes traditional synchronous replication solutions, because they create a primary-secondary relationship between the active (primary) LUN, where data is being accessed, and the secondary LUN, that is being replicated to. When the VM is accessing the secondary LUN, replication is stopped, or reversed, and the LUN is made visible to hosts. The, former secondary, LUN has a completely different LUN ID and is available copy of the former primary LUN. This setup works for traditional disaster recovery–type configurations, because it is expected that VMs must be started up on the secondary site. The Stretched Cluster configuration requires simultaneous, uninterrupted access to enable live migration of running VMs between sites.
The storage subsystem for a stretched cluster must be able to be read from and write to both locations simultaneously. All disk writes are committed synchronously at both locations to ensure that data is always consistent regardless of the location from which it is being read. This storage architecture requires significant bandwidth and very low latency between the sites in the cluster. Increased distances or latencies cause delays in writing to disk and a dramatic decline in performance. They also preclude successful vMotion migration between cluster nodes that reside in different locations.
https://core.vmware.com/resource/vmware-vsphere-metro-storage-cluster-vmsc#section1
Uniform vs. non-uniform
There are two main stretched cluster storage architectures based on a fundamental difference in how hosts access storage:
- Uniform host access configuration
- Nonuniform host access configuration
In a uniform architecture, ESXi hosts from both sites are all connected to a storage node in the storage cluster across all sites. Paths presented to ESXi hosts are stretched across a distance.
This design provides full storage access, can handle local storage failure without interruption, and helps provide a better level of uptime for virtual machines.
For this type of architecture, we create affinity rules to define the primary site for a VM to localize all the storage I/O locally in each site to reduce cross-site traffic.
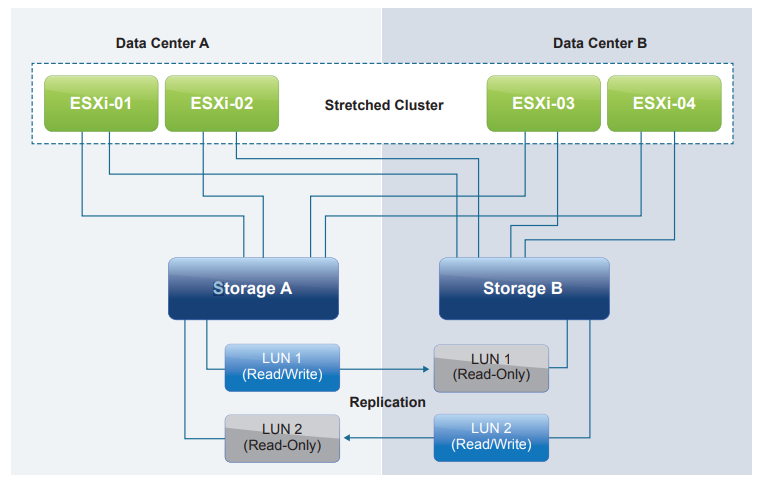
In a non-uniform architecture, ESXi hosts at each site are connected only to the storage node(s) at the same site. Each cluster node has read/write access to the storage in one site but not to the other.
This configuration gives each datastore implicit “site affinity” due to the “LUN locality.” If anything were to happen with the link between the sites, the storage system on the preferred site for a given data store would be the only one with read/write access. This prevents any data corruption in case of a failure scenario.
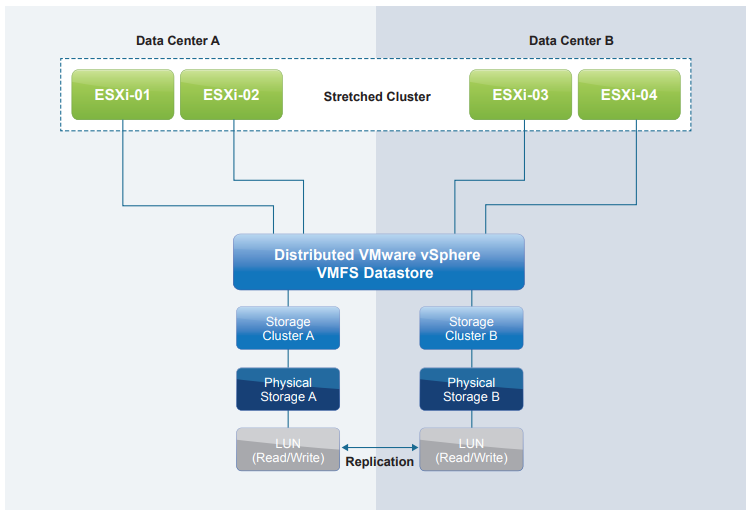
Within one stretched cluster, one presentation model should be implemented.
Synchronous vs. Asynchronous
A stretched cluster usually uses synchronous replication to guarantee data consistency (zero RPO) between both sites. Synchronous replication writes data to primary storage and the replica simultaneously. That way, the primary copy, and the replica always remain synchronized.
Asynchronous replication products write data to primary storage first and then copy the data to the replica, so there is a delay before data is copied to the secondary site.
For both data replication techniques, a storage array on Site A will send an acknowledgment of the transaction to the host on Site A. Where the two techniques differ is the order of events that take place after the hosts sends the transaction the local storage array.
With asynchronous replication, the following happens:
- Site A host sends a write transaction to the Site A storage array.
- Site A storage array sends the transaction to the cache and sends an acknowledgment to the host.
- Site A storage array sends the update to the Site B storage array after a delay.
- Site B storage array sends an acknowledgement to the Site A storage array.
In synchronous replication, just like with asynchronous replication, the Site A host sends a write transaction to the Site A storage array. But with synchronous replication, the next steps in the process differ as follows:
- Site A storage array commits the transaction to cache and immediately sends the update to the Site B storage array.
- Site B storage array sends an acknowledgment back to the Site A storage array.
- Site A storage array sends an acknowledgment to the host.
With synchronous replication, both arrays process the transaction before an acknowledgment is sent to the host, meaning the arrays will always be in sync. In asynchronous replication, the secondary storage array is usually a few transactions behind the primary array.
Further Design and configuration aspects
Split-brain avoidance
A split-brain is where two arrays might serve I/O to the same volume without keeping the data in sync between the two sites. Any active/active synchronous replication solution designed to provide continuous availability across two different sites requires a component referred to as a witness to mediate failovers while preventing split brain. Typically this witness is an application running on a VM in a third fault domain, meaning it has a separate infrastructure that runs at a third location (Data Center) that can reach the two legs of the Stretched cluster independent of which site is up.
VMware vSphere HA
Enabling vSphere HA admission control enables workload availability. To ensure that all workloads can be restarted by vSphere HA on just one site, configuring the admission control policy to 50 percent for both memory and CPU is recommended. Use a percentage-based policy because it offers the most flexibility and reduces operational overhead.
Data locality
Cross-site bandwidth can be crucial and critical in a stretched cluster configuration. For this reason, you must “force” access to local data for all VMs in a uniform model (for non-uniform data, the locality is implicit). Using vSphere DRS and proper path selection can achieve this goal.
VMware vSphere DRS and storage DRS
Create “should run” vSphere affinity rules, you want the VMs to restart on the other side of the cluster in case of one leg fails, to pin the VMs to one side of the cluster. Note that vSphere DRS communicates these rules to vSphere HA, which is stored in a “compatibility list” governing allowed start-ups. If a single host fails, VM-to-host “should rules” are ignored by default.
Conclusion
We have learned that we need to choose a storage technology that either supports Uniform or non-uniform storage architecture and writes to the storage either with synchronous or asynchronous replication.
We would choose a uniform storage architecture with a use case to provide the applications or workloads with as high as possible disaster avoidance. We would further choose Synchronous replication. We would ensure that anything written is written to both sides of the Stretch Cluster storage simultaneously. In the event of an ESXi failure, that data can be read from any surviving hosts.
Since we are choosing this type of architecture to capitalize on the maximum possible disaster avoidance, we should strive to treat each leg of the Stretched Cluster as a critical infrastructure of itself. Ensure that we have redundant power, cooling, network, and fiber between the stretched cluster’s two legs. If we build each cluster end to have the maximum possible uptime, we ensure we have a real disaster-avoidant solution. If or when we lose one leg of the cluster completely, it will take significant time to bring the cluster back up. The workloads need to be able to run on one leg for extended of time with all the bells and whistles of a modern disaster avoidant solution. We need enough storage on each side to run all the workloads of the cluster as well as being able to lose a disk shelf, a storage controller, etc. We need enough ESXi hosts to be able to run all the workloads and still be able to lose ESXi hosts without bringing the services down.
The vSphere Compute layer and the networking is also essential, although, as you have noticed, this article addresses the storage primarily.
Many vendor-specific solutions exist for a Stretched cluster, like Dell VxRail, Cisco/Netapp MetroCluster, Cisco Hyperflex, and others.
However, the plan when creating a working solution for disaster avoidance should be.
- Decide the type of storage Architecture you want to use
- Design one data center for the highest level of disaster avoidance you can afford
- Duplicate that design to data center 2
So we design one data center to run all the workloads with a high degree of resilience, and then we purchase 2x of that and add one infrastructure in each of the DCs.
It is important to stress this solution does provide the ability to survive some disasters. However, it is not to be considered a DR solution. Due to the nature of the latency required, the two legs of the cluster need to be close to each other. We can do design alterations to a Stretched cluster to add DR elements to it, just as any other infrastructure design.