I work in a manufacturing organization. I design and build systems to support the production of Biologicals that will be injected into patients. Unplanned downtime impacts our ability to deliver products to the market. The biologicals go through maturing phases in bioreactors, taking several days to weeks. Since this kind of business is highly regulated to ensure the safety of the patients, manufacturers like us must monitor the drugs throughout the manufacturing phase. Unplanned downtime here may lead to gaps in monitoring data, which may lead to products having to be discarded.
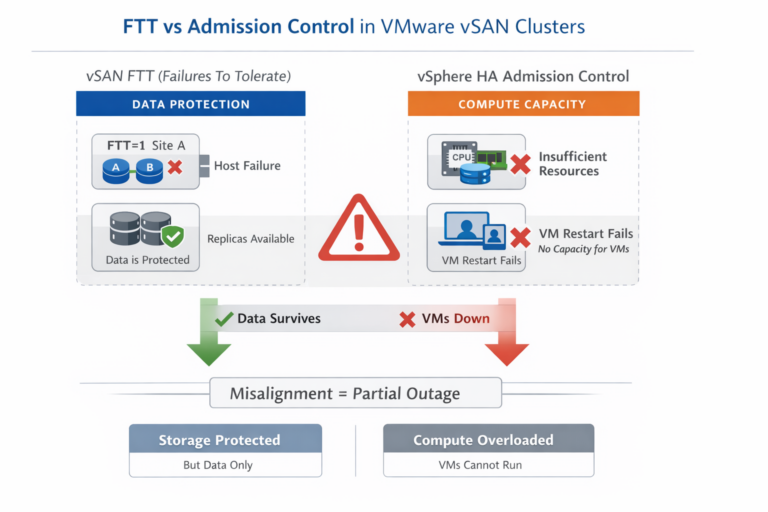
When designing compute environments to support manufacturing, I have to ensure that the infrastructure has enough redundancy and resilience to not be able to be providing applications uptime, or a run environment even though parts of the infrastructure would fail.
Previously, I have written about some of my considerations:
The TWI Institute has researched the cost of unplanned downtime for manufacturing organizations. According to them, the average manufacturing downtime costs $260k per hour, and the average manufacturing plant has 15 hours of downtime per week, which would be $3.9M per week.
The cost for different businesses is different, and it is also based on the company’s production and the size of the operation. However, we can conclude that it is substantial.
The cost of unplanned downtime can be calculated by accounting for lost revenue or time. The lost time formula can be applied to individual machines, machine parts, shifts, departments, or manufacturing plants.
Lost time formula:
Unplanned Downtime = (Time Asset is Down / Total Time) x 100
Lost revenue is highly dependent upon the organization’s size, the number of employees affected, the duration of the downtime and the complexity of the cause.
Lost cost formula:
Cost of Unplanned Downtime = Average Hourly Wage x (Time Asset is Down/Total Time) X Number of Employees Affected
Depending on the individual variables, the result could be a few hundred to a few million dollars. Associated costs such as litigation, facility repairs or equipment replacements can increase the total significantly.
As I addressed in the article on considerations to create disaster avoidant designs, many aspects must go into the design. Disaster avoidance and disaster recovery represent significant cost increases for IT systems, and the thought process explains well why some IT systems are expensive.
For the type of Compute Systems that I design and build, we have two types of disaster avoidant designs. Stretched Clusters – where two infrastructures are located in two data centers within the same campus and storage replicates synchronously. This ensures that data exists in both data centers.
The other one, which I will address in my next article, is two independent compute infrastructures replicating each other. The failover between the infrastructures will be facilitated with VMware Live Recovery (Previously SRM).