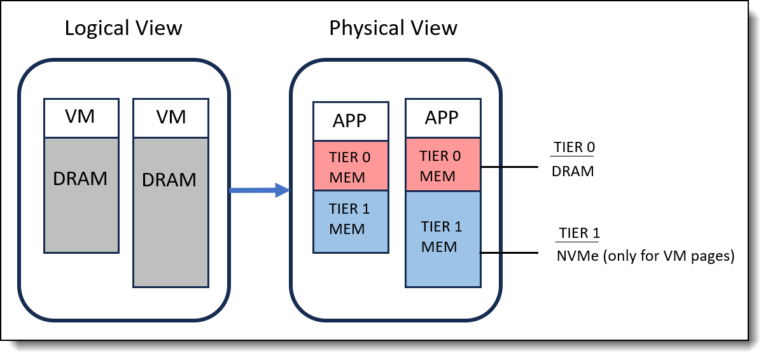
As I mentioned in the last article, I will write a new article about a disaster-avoidant solution I am deploying where it makes sense.
Disaster avoidance in this setting means that we have a platform that is able to absorb some level of disaster. We can loose hardware components within one data center like storage nodes, compute nodes, switches, power supplies, power input, power source, WAN connections etc. But we can also move all workloads to a different data center automatically if we would loose the whole data center. I have written about some of the considerations for that here:
In my designs I operate with two types of Disaster Avoidant Solutions.
- Synchronous Replication
- Asynchronous replication
In this article I will address the latest setup of Asynchronous replication that I have been designing for.
One of the Hyper Converged Infrastructures I work with is the Dell PowerFlex (PFx). Over the years it has gone through massive innovation, changed name from VxRack, ScaleIO, and changed the type of hardware nodes it provides. Currently it typically comes with a control or management cluster, Compute Nodes, Storage Nodes, and Cisco Switches. I am a big fan of this HCI and I will most likely produce some articles on the infrastructure later.
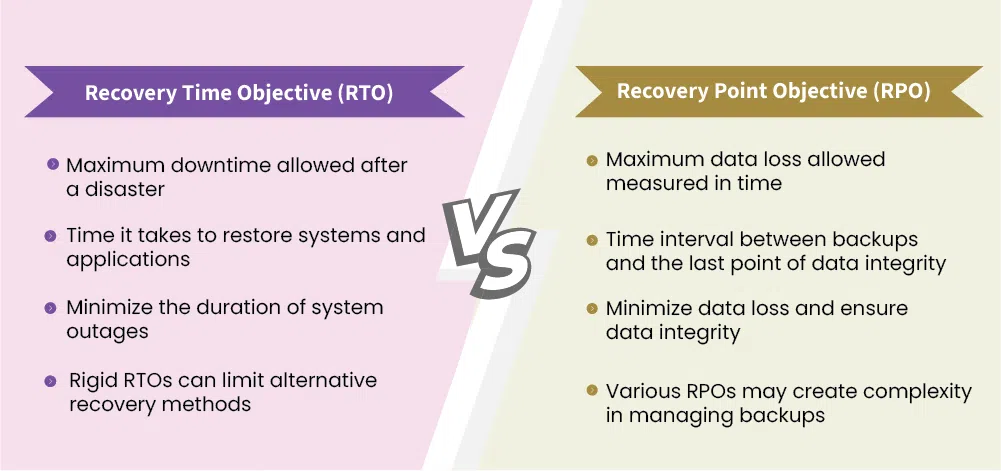
The Dell PFx system does at current not deliver a Metro Stretched Cluster Solution. The solution supports very impressive RPO/RTOs, but not 0. To use a design for Asynchronous replication you have to know your applications agreed upon RPO/RTOs and know that what the hardware solution offers is better than what the applications demand.
I have added an explanation of RTO vs RPO underneath
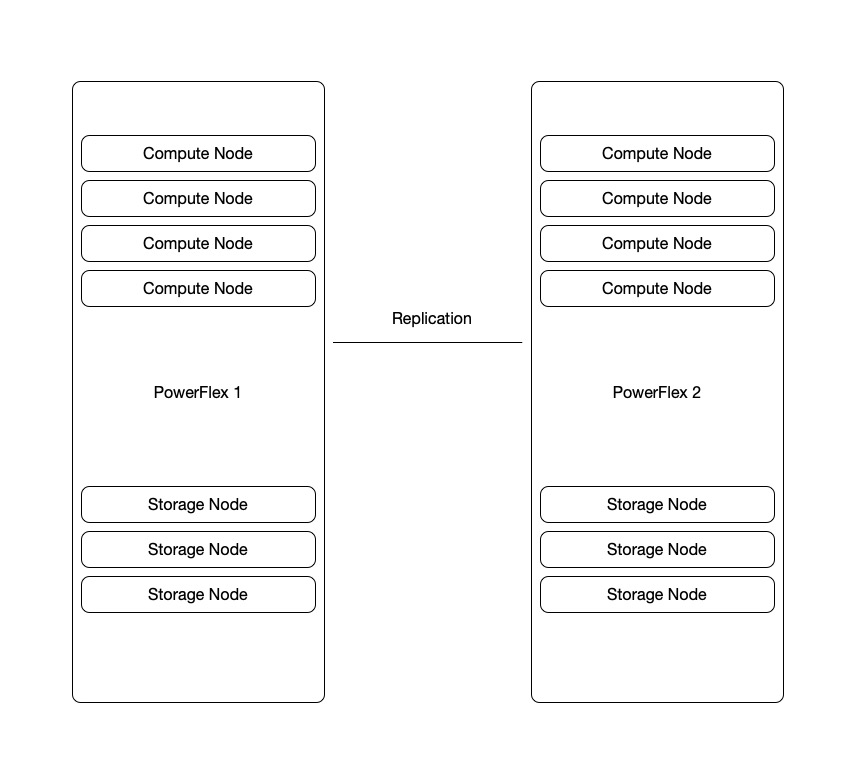
In the figure above we have two sample PowerFlex Racks. For this visual they have the same hardware layout, but that is not required. It is more important that they are both on the same VMware and PowerFlex Software version.
Types of replication
Asynchronous replication between one PFx to another PFx can take place using a few different technologies. The most common are either Array based replication, vSphere Replication. The different options introduce different requirements for latency and bandwidth, and they introduce different levels of achievable RPO.
Choosing between vSphere Replication and PowerFlex Array-Based Replication
Both VMware vSphere Replication (vSR) and Dell PowerFlex Array-Based Replication serve the purpose of disaster recovery (DR), disaster avoidance (DA), and business continuity, but they differ significantly in architecture, functionality, and use cases. The choice depends on factors such as performance, scalability, recovery objectives, and infrastructure design.
Key differences and when to choose each solution
| Feature | vSphere Replication (vSR) | PowerFlex Array-Based Replication |
|---|---|---|
| Replication Type | Hypervisor-based, VM-level replication | Storage array-based, block-level replication |
| Scope of Replication | Replicates individual VMs and their virtual disks | Replicates entire storage volumes (LUNs or storage pools) |
| RPO (Recovery Point Objective) | As low as 5 minutes | As low as seconds |
| RTO (Recovery Time Objective) | Medium (manual or automated VM recovery via VMware Live Recovery (SRM)) | Faster (instant storage volume activation) |
| Replication Mode | Asynchronous | Asynchronous |
| Bandwidth Efficiency | Uses Changed Block Tracking (CBT) to replicate only changed data | Uses delta-based replication with a journal-based approach |
| Storage Independence | Works with any vSphere-supported storage (vSAN, VMFS, NFS, vVols) | Works only with PowerFlex storage |
| Multi-Site and Cloud Support | Supports multi-site DA and replication to VMware Cloud on AWS (VMC on AWS) | Supports multi-site DA but is limited to PowerFlex storage environments |
| Management Interface | Managed through vCenter Client | Managed through PowerFlex Manager |
| Use Case | VM protection, DR for VMware workloads | Data center-level DR, large-scale storage replication |
If your primary concern is VM-level protection and ease of use, vSR is the better choice. If you require enterprise-wide, low-latency storage replication for business-critical applications, PowerFlex replication is the better fit.
Failover Process: VMware vSphere Replication vs. PowerFlex Array-Based Replication
We need to understand the impact of the chosen solution when it comes to fail-over to the destination site.
Failover Workflow in vSphere Replication
Step 1: Detecting Primary Site Failure
- vCenter and vSphere Replication Appliance (VRAs) at the target site detect that the source site is no longer reachable.
- Admin initiates a failover action manually via the vCenter or automatically via Live Recovery (previously SRM).
Step 2: Registering and Reconfiguring Replicated VMs
- The target site’s vSphere Replication Appliance (VRA) registers the replicated VM files in the vCenter inventory.
- vSphere Replication (vSR) recreates the VM’s configuration, including compute, network, and storage mappings.
Step 3: Restoring VM Data from Replicated Storage
- vSR replays the most recent recovery point (or an earlier Point-in-Time snapshot, if configured).
- Snapshots ensure flexibility in case of corruption, ransomware, or database inconsistencies.
Step 4: Powering On and Testing the VM
- Once registered, the VM is powered on at the target site.
- The administrator verifies application connectivity, IP settings, and performance.
Step 5: Failback to Source Site (Optional, After Recovery)
- Once the source site is restored, reverse replication can be set up to sync changes back.
- Failback requires an initial synchronization and a planned switchover before production is moved back.
Diagram: vSphere Replication Failover Process
[Primary Site] [Target Site]
┌─────────────────────┐ ┌─────────────────────┐
│ vCenter Server │ │ vCenter Server │
│ vSphere Hosts │ │ vSphere Hosts │
│ vSphere VMs │──Replicates──►│ Replicated VMs │
│ vSphere Storage │ │ Target Datastore │
│ vSphere Replication Appliance │ vSphere Rep Appl |
└─────────────────────┘ └─────────────────────┘
▼
[Failure Detected]
▼
[Manual or Automatic Failover]
▼
[Register VMs] → [Recover Data] → [Power On VMs]
▼
[Business Resumes]
Failover Workflow in PowerFlex Replication
Step 1: Detecting Source Site Failure
- PowerFlex Manager detects that the primary storage array is down or unreachable.
- The administrator triggers a failover event via PowerFlex Manager or an automated script/API.
Step 2: Promoting Replicated Volumes at the Target Site
- The PowerFlex storage system at the target site promotes the replicated volumes, making them writable.
- Unlike vSphere Replication, which restores VMs, PowerFlex instantly activates entire storage volumes.
Step 3: Reconnecting Compute Resources
- Compute nodes (ESXi, Kubernetes, or bare metal servers) at the target site are mapped to the newly promoted storage.
- VMs or applications automatically detect and mount the replicated storage.
Step 4: Application Validation and Business Continuity
- Applications hosted on the replicated storage are restarted at the secondary site.
- Network configurations (IP changes, DNS updates) may be required for external connectivity.
Step 5: Failback After Primary Site Recovery
- After the source site is restored, a reverse replication syncs changes back before migrating workloads back to the primary site.
- PowerFlex allows instant failback by resynchronizing delta changes rather than performing a full copy.
Diagram: PowerFlex Array-Based Replication Failover Process
[Primary Storage] [Target Storage]
┌─────────────────────┐ ┌─────────────────────┐
│ PowerFlex Nodes │ │ PowerFlex Nodes │
│ Storage Pools │──Replicates──►│ Replicated Volumes│
│ Production Data │ │ Journal Storage │
│ Applications/VMs │ │ Standby Compute │
└─────────────────────┘ └─────────────────────┘
▼
[Failure Detected]
▼
[Promote Replicated Volumes]
▼
[Reconnect Compute & Applications]
▼
[Instant Storage Access]
Comparison of Failover Mechanisms
| Factor | vSphere Replication (vSR) | PowerFlex Array-Based Replication |
|---|---|---|
| Failover Granularity | VM-Level (per-VM recovery) | Storage-Level (volume-based failover) |
| Time to Failover | Moderate (VM registration, data recovery needed) | Faster (Instant promotion of replicated volumes) |
| Application Awareness | Can restore VM snapshots for consistency | More suited for databases and applications requiring near-zero RPO |
| Networking Adjustments | May require IP reconfiguration (Live Recovery helps automate this) | Requires manual or automated network reconfiguration |
| Failback Complexity | Requires a new sync before failback | Direct failback with delta-based replication |
Which Failover Approach
- Choose vSphere Replication if you need a VM-centric failover mechanism that allows flexible per-VM recovery, supports multi-vendor storage, and integrates with VMware Cloud for DR.
- Choose PowerFlex Array-Based Replication if you need faster failover times, low RPO (seconds), and instant access to storage volumes for large-scale applications and databases.
Which replication solution to choose
The final key to understand is the bandwidth requirements that follow each architectural choice. As we have seen Array based replication is faster, and we may think
Bandwidth Requirements
The required bandwidth depends on:
- Replication RPO (Recovery Point Objective):
- Lower RPO (near real-time replication) requires higher bandwidth.
- Higher RPO (e.g., 15-30 minutes) allows data transfers in batches, reducing bandwidth needs.
- Change Rate (Delta Changes per Second):
- Applications with high write intensity (e.g., databases, virtualized workloads) require more bandwidth.
- Example: A 5 TB storage volume with a 5% change rate per hour needs to replicate 250 GB per hour (~70 Mbps continuous throughput).
- Compression & Deduplication Efficiency:
- PowerFlex uses data compression to reduce transfer size
- Effective bandwidth usage can be calculated as:
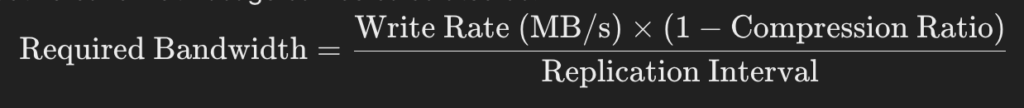
4. Number of Concurrent Replicated Volumes:
- If multiple volumes are replicated simultaneously, bandwidth usage scales accordingly.
Latency Requirements
PowerFlex replication operates asynchronously, meaning latency impacts replication efficiency but not application performance.
- Recommended Maximum Latency:
- <5 ms (ideal for near-real-time replication).
- 5-20 ms (acceptable for RPO >5 minutes).
- >20 ms may cause replication lag and increased journal size.
- Impact of Latency:
- High latency increases the time it takes to acknowledge writes at the target site.
- Large delays increase journal storage usage, requiring more space at the target.
Minimum and Recommended Network Specifications
| Requirement | Minimum | Recommended for Near-Real-Time DR |
|---|---|---|
| Bandwidth | 1 Gbps | 10 Gbps or higher |
| Latency | ≤ 20 ms | ≤ 5 ms |
| Packet Loss | < 0.1% | Near 0% |
| Jitter | < 5 ms | < 1 ms |
Example Bandwidth Calculation
Scenario: Replicating a 10 TB Database with 10% Daily Change Rate
- Change rate: 1 TB per day → ~42 GB per hour
- Compressed transfer (50%): 21 GB per hour (~50 Mbps required continuously)
- Peak load handling: If replication is performed in 5-minute intervals, bandwidth must support ~1.75 GB per interval (~50 Mbps).
Scenario: Replicating 10 VMs (Each 100 GB) with a 5% Change Rate Per Hour
- Change rate: 5 GB per VM per hour × 10 VMs = 50 GB/hour
- Compressed transfer (~50% savings): ~25 GB/hour (~55 Mbps continuous bandwidth required)
- For a 15-minute RPO: Data transferred every 15 minutes, requiring ~220 Mbps burst bandwidth.
Best Practices for Optimizing Bandwidth and Latency
Use a dedicated replication network: Prevents congestion with production traffic.
Enable compression and deduplication: Reduces the amount of data transferred.
Monitor replication lag: Adjust RPO or bandwidth allocation if delays occur.
Use QoS and traffic shaping: Prioritize replication traffic during peak hours.
Conclusion
Asynchronous replication offers a full worthy Disaster Avoidance solution. There are when going with PowerFlex HCI at least two different ways to target replications. Going with vSphere Replication allows a granular choice of VMs, not all VMs of a storage array need to be in scope. The downside is that there needs to be more room to handle data loss,but the requirements of latency and bandwidth on the synchronization is less. ProwerFlex Array replication allows for lower RPO, but it has lower latency requirements and it targets whole storage arrays. Either solution can be the right one for yo, but it is important to understand when to use the different options.