VMware stretched clusters are frequently treated as the gold standard of availability design. They promise zero recovery point objective, automated failover, and the comforting idea that an entire site can disappear without anyone noticing. In presentation decks and architecture diagrams, the concept is elegant: a single logical cluster spanning two locations, maintaining synchronous data copies and relying on vSphere HA to absorb what would otherwise be catastrophic failures.
The appeal is understandable. In a world that equates availability with success, stretched clusters seem to offer a definitive answer. Yet architecture is rarely about definitive answers. More often, it is about choosing which problems to solve explicitly and which to accept openly. From that perspective, stretched clusters are not inherently wrong—but they are very often the wrong tool for the problem organizations are actually trying to solve.
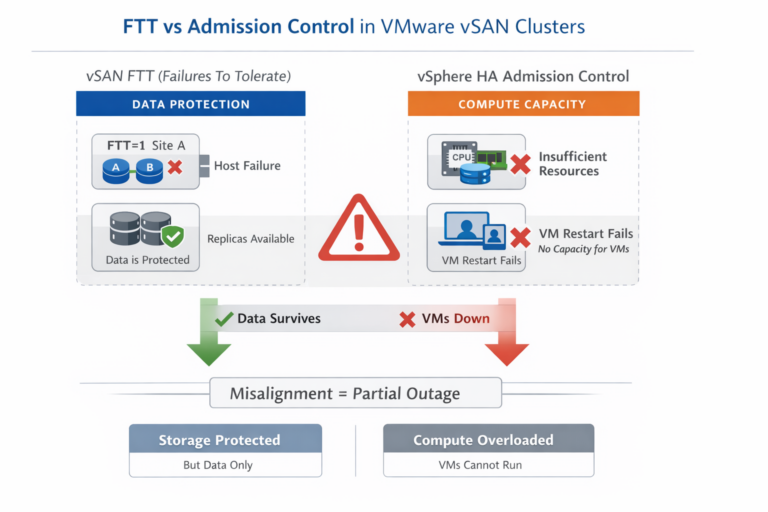
At its core, a VMware stretched cluster addresses a single, very specific scenario: the loss of an entire site while maintaining continuous access to up‑to‑date data. It does this by synchronously replicating storage objects across sites and using a witness to arbitrate quorum. When one site fails, workloads restart on the surviving site with no data loss. Within those narrow conditions, the design is effective and technically sound.
What is often misunderstood is how limited that protection truly is. A stretched cluster does not protect data from being corrupted, deleted, encrypted by ransomware, or damaged by human error. In fact, because replication is synchronous, it faithfully mirrors destructive changes as efficiently as it mirrors healthy ones. From an availability standpoint, this behavior is correct. From a recovery standpoint, it offers no safety net. The environment continues running, even as it propagates the very failure administrators assume the architecture protects them from.
This distinction matters because organizations rarely adopt stretched clusters solely for site‑failure scenarios. More often, they are chosen as a general substitute for disaster recovery—a way to avoid designing recovery workflows, testing restoration procedures, or accepting even brief downtime. In doing so, stretched clusters are asked to answer questions they were never designed to address.
Network constraints expose the next reality check. Stretched clusters depend on tight latency, consistent bandwidth, and highly predictable connectivity between sites and to the witness. These are not theoretical requirements. Storage acknowledgement, write completion, resynchronization behavior, and failure detection all depend on them. While environments may meet these thresholds at deployment time, real networks drift. Traffic patterns change, workloads evolve, and previously unused capacity becomes contested. When conditions deteriorate, stretched clusters do not degrade in a graceful or easily diagnosable way. Latency increases lead to IO stalls, resync storms compete with production workloads, and quorum decisions become conservative. The system is still “up,” but its behavior becomes erratic at precisely the moment operators need certainty.
The architectural cost of this sensitivity is often underestimated because it is distributed rather than visible. A stretched cluster introduces fault domains, site preferences, witness dependencies, special DRS behaviors, and affinity rules that must all remain aligned. Each component is understandable in isolation. Together, they form a system whose behavior under failure cannot be reasoned about intuitively. When something goes wrong, operators are forced to recall configuration nuances rather than rely on clear cause‑and‑effect relationships. Failure analysis slows, not because people are unskilled, but because the environment demands perfect memory instead of clear boundaries.
Symmetry is another assumption on which stretched clusters quietly depend. Hardware, firmware, networking, capacity management, and operational discipline are expected to remain balanced across sites for years at a time. In real organizations, symmetry erodes. One site becomes a little older, a little more constrained, a little harder to maintain. These drifts are rarely dramatic enough to justify redesign, yet they accumulate into systemic bias. Stretched clusters do not absorb asymmetry well; they amplify it, turning small differences into recurring operational friction.
Perhaps the most consequential misunderstanding, however, is conceptual. Stretched clusters are often sold—and adopted—as disaster recovery solutions. They are not. They are disaster avoidance mechanisms. They keep workloads running, but they do not help administrators recover correctly after something has gone wrong. Recovery requires the ability to rewind time, to inspect damage, to restore clean state deliberately. Continuous availability without recoverability is not resilience; it is persistence. For organizations facing modern threats—ransomware, regulatory scrutiny, frequent change—the difference is existential.
There is also an uncomfortable truth beneath many stretched cluster designs: they are frequently deployed to compensate for application limitations. Applications that cannot tolerate short outages, lack state separation, or were never designed with failure in mind often push resilience demands downward into the infrastructure. Rather than addressing those application constraints directly, organizations stretch the platform. This works, but it solves the problem at the most expensive layer possible. Infrastructure complexity grows indefinitely to preserve application assumptions that could have been revisited at far lower cost.
None of this means stretched clusters have no place. They can be appropriate for a small number of truly mission‑critical workloads, where synchronous consistency is essential, networking conditions are exceptional, and failure scenarios are actively tested rather than assumed away. Those environments tend to be very clear about why the design exists and very disciplined about its scope.
The problem is not that stretched clusters are flawed—it is that they are precise solutions applied to imprecise problems. Architecture is not about eliminating failure altogether. It is about deciding which failures are acceptable, visible, and recoverable. VMware stretched clusters often trade recoverability and operational clarity for the comfort of uninterrupted uptime. That trade is not inherently wrong, but it is rarely examined honestly.
In practice, many organizations would be better served by simpler designs: clear site boundaries, purpose‑built clusters, asynchronous replication, and recovery workflows that are understood, tested, and trusted. These designs may accept brief downtime, but they fail predictably and recover cleanly. They privilege comprehension over illusion.
A VMware stretched cluster is not the culmination of good architecture. It is a specialized tool. Used carefully, it can be powerful. Used reflexively, it becomes a fragile answer to questions that were never fully asked.