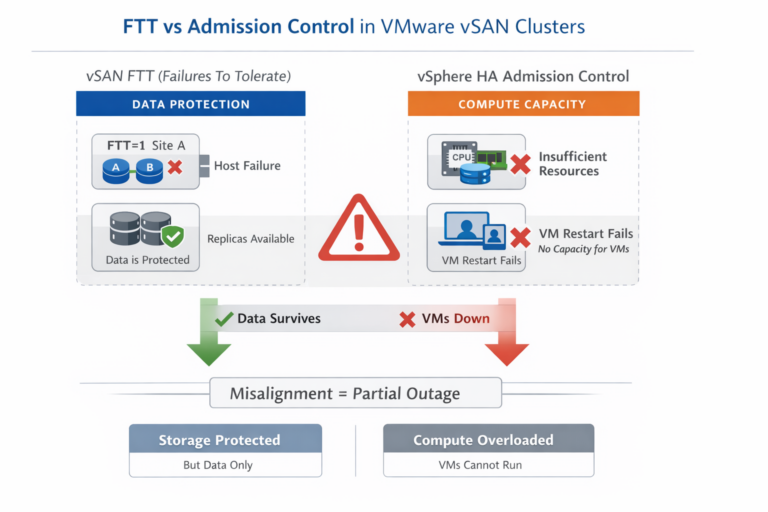
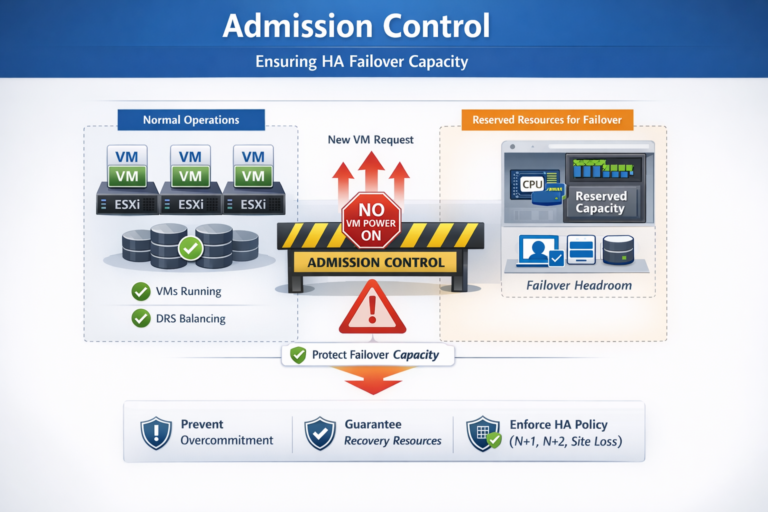
Use this table to determine whether a stretched cluster is the right architectural choice for a given environment.
How to Use This Matrix
- If you answer YES to all items in the Use column, a stretched cluster may be appropriate.
- A single NO in a critical row should trigger consideration of alternatives (Live Site Recovery (formerly SRM), async replication, per‑site clusters).
✅ Decision Matrix
| Decision Area | Question to Ask | Stretched Cluster: YES When… | Stretched Cluster: NO When… |
| Business Requirement | Is zero data loss (0 RPO) a documented business requirement? | Any data loss is unacceptable, including seconds. | Minutes or even seconds of data loss are acceptable. |
| Outage Tolerance | Can the business not tolerate restart‑based recovery? | Workloads must survive site loss with only HA restarts. | Brief downtime during recovery is acceptable. |
| Recovery Strategy | Is disaster avoidance preferred over recovery? | Goal is to continue running through site failure. | Goal is clean recovery to a known‑good state. |
| Data Protection Model | Do you understand synchronous replication mirrors bad data too? | You explicitly accept this and have separate backups. | You expect the platform to help with recovery/rollback. |
| Network Latency | Can you guarantee < 5 ms RTT between sites long‑term? | Low, stable latency is contractual and monitored. | Latency is variable, shared, or “usually acceptable.” |
| Network Bandwidth | Can you sustain 10+ Gbps under failure and resync? | Capacity is sized for worst‑case resync scenarios. | Bandwidth is sized for steady‑state only. |
| Network Predictability | Can latency remain stable during congestion or failure? | Network behavior is deterministic under stress. | Congestion or jitter is expected during incidents. |
| Site Symmetry | Can both sites remain operationally symmetric for years? | Hardware, firmware, capacity, and ops are aligned. | One site is newer, smaller, or differently managed. |
| Scope Control | Is this for a small, well‑defined workload set? | Only a few Tier‑1 workloads will use it. | Platform is intended as a general‑purpose cluster. |
| Operational Maturity | Do teams understand HA/DRS/fault‑domain interactions? | Staff are trained and failure scenarios are tested. | Teams prefer simple, explicit recovery workflows. |
| Failure Clarity | Do you accept more complex failure diagnostics? | Complex behavior is acceptable for less downtime. | Simplicity during incidents is a priority. |
| Application Design | Are apps unable to tolerate restart or short outage? | Apps require near‑continuous availability. | Apps can restart or be redesigned to tolerate failure. |
| Change Velocity | Is the environment relatively stable over time? | Changes are controlled and infrequent. | Frequent changes, migrations, or platform churn. |
| Security/Ransomware | Do you already rely on backups for data recovery? | Backups are primary recovery mechanism. | You expect the infrastructure to aid recovery. |
| Cost Acceptance | Are you willing to pay for permanent complexity? | Cost and complexity are justified by the requirement. | Complexity is acceptable only if it’s removable. |
✅ When the Matrix Says “YES”
A VMware stretched cluster is appropriate when:
- Zero RPO is non‑negotiable
- Network guarantees are strict and sustainable
- Workloads are few and clearly scoped
- The organization understands this is disaster avoidance, not DR
❌ When the Matrix Says “NO”
Favor alternatives when:
- Recovery clarity matters more than uninterrupted runtime
- Networks are shared or unpredictable
- Long‑term site symmetry cannot be guaranteed
- The platform is expected to compensate for application limitations
Common alternatives:
- Independent clusters + Live Site Recovery
- Async replication
- Purpose‑built clusters per site
- Explicit, tested recovery workflows