Side‑by‑Side Architectural Comparison
| Category | VMware Stretched Cluster | VMware Live Site Recovery (VLSR) |
| Primary Purpose | Disaster avoidance through continuous availability | Disaster recovery through orchestrated failover and failback |
| Failure Model | Survive site failure while workloads continue running | Accept outage, then recover workloads cleanly |
| Recovery Point Objective (RPO) | Near‑zero / zero RPO via synchronous replication | Configurable RPO, typically minutes (async replication) |
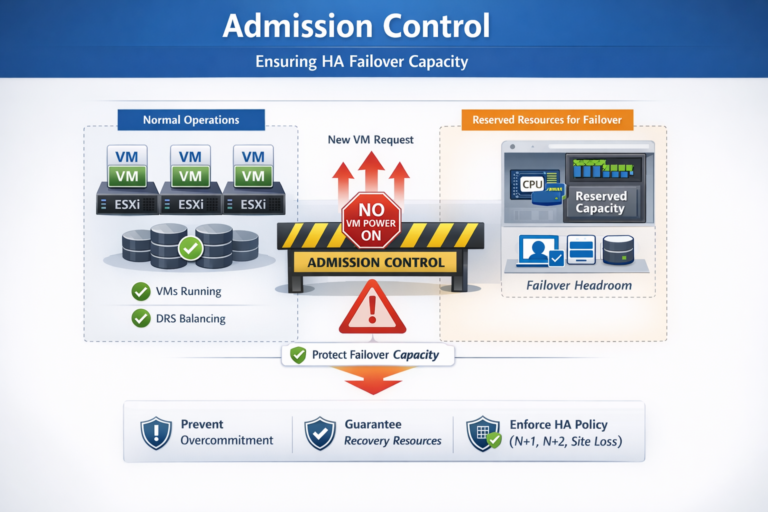
| Recovery Time Objective (RTO) | Very low; VM restart via HA | Predictable but higher; coordinated recovery plan execution |
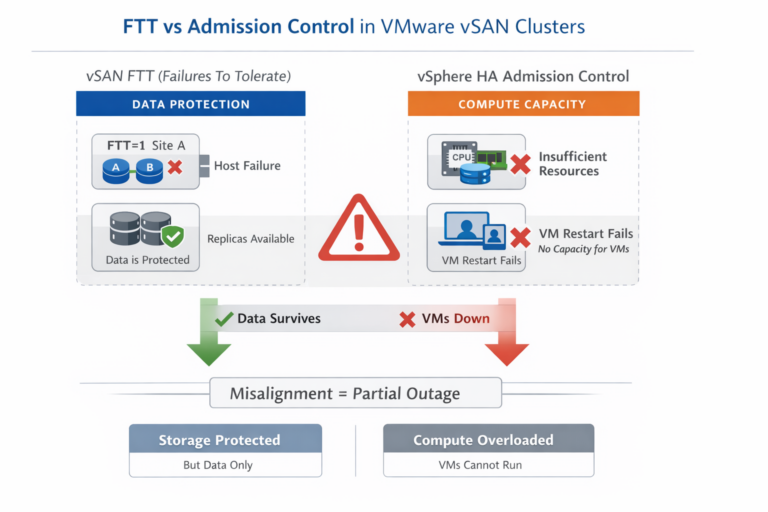
| Data Protection Scope | Infrastructure failure only | Infrastructure, logical failure, and operational failure |
| Ransomware / Data Corruption Protection | No – corruption and deletion replicate instantly | Yes – point‑in‑time recovery supported |
| Recovery Flexibility | None – no rollback capability | High – recovery to earlier known‑good states |
| Operational Model | One logical cluster across two sites | Two independent sites with runbooks and orchestration |
| Network Requirements | Strict: <5 ms RTT, high sustained bandwidth | Relaxed: no stretched network required |
| Network Failure Sensitivity | High; degradation under latency/jitter | Low; replication tolerates disruption |
| Site Symmetry Requirement | Mandatory long‑term hardware and ops symmetry | Not required; sites may differ |
| Operational Complexity Under Failure | High; multiple interacting subsystems | Lower; explicit recovery steps |
| Failure Diagnosability | Difficult under stress | Clear and deterministic |
| Testing Capability | Limited; live‑site testing is complex | Built‑in, non‑disruptive DR testing |
| Planned Migration Use Case | Seamless mobility with strict constraints | Native support via planned migration workflows |
| Management Boundary | Blurred; single cluster spanning sites | Clear; hard separation of fault domains |
| Application Fit | Apps that cannot tolerate restart/outage | Apps that tolerate restart for recoverability |
| Change Velocity Tolerance | Low – changes ripple across sites | High – sites evolve independently |
| Architectural Coupling | Very tight (compute, storage, network) | Loosely coupled by design |
Architectural Summary
✅ Choose Stretched Cluster:
- Zero RPO is a hard business requirement
- Network latency and bandwidth can be guaranteed long‑term
- Workloads are few, critical, and stable
- Objective is continuous operation, not recovery
- Organizational maturity supports high operational complexity
✅ Choose VMware Live Site Recovery (VLSR):
- Recoverability matters more than uninterrupted uptime
- Ransomware, corruption, or operator error are real risks
- Network conditions are variable or shared
- Applications can tolerate restart for correct recovery
- You value testable, auditable DR workflows
Architectural Bottom Line
A stretched cluster minimizes interruption.
VLSR maximizes recoverability.
They solve different problems.
Stretched clusters protect runtime.
VLSR protects the outcome.
As an architect, the decision should never start with “Which is more advanced?”
It should start with “Which failure do we need to survive—and which do we need to recover from?”